อธิบายพื้นฐาน CNN พร้อมโค้ด PyTorch🔥
เนื้อหาในบทความนี้ได้แก่
2.3 Fully-connected Layer หรือ Dense Layer
3. ตัวอย่างการสร้าง CNN (VGG16) ด้วย PyTorch อย่างง่าย
1. เกริ่นนำ
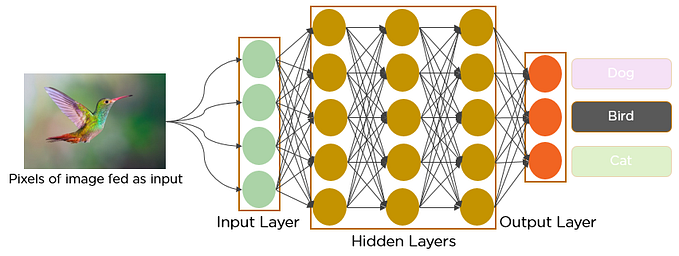
ตั้งแต่อดีตจนถึงปัจจุบัน Artificial Neural Network (ANN) คือโมเดลสำหรับงานด้านการจดจำ pattern (pattern recognition) และเป็นหัวใจของ deep learning
แต่ก็มีข้อจำกัดคือ การคำนวณข้อมูลรูปภาพโดยใช้ Artificial Neural Network โดยตรงนั้นมีความซับซ้อนในการประมวลผลมาก ยกตัวอย่างเช่น input เป็นรูปภาพสีขนาด 64 × 64 นั้น weight ที่ต้องใช้ใน hidden layer แรกก็ปาเข้าไป color channel × height × width = 3 × 64 × 64 = 12,288 แล้ว ไม่ต้องพูดถึง bias หรือ weight ที่ต้องใช้ใน layer อื่นๆอีก จากความเยอะนี้จึงนำไปสู่ปัญหา 2 อย่างคือ
- ใช้พลังงาน และเวลาในการประมวลผล ANN ขนาดใหญ่นี้มาก
2. มีความเป็นไปได้สูงที่จะเกิด overfitting เนื่องจากมีจำนวน parameter มากเกินไป
CNN หรือ Convolutional Neural Network จึงถูกคิดค้นขึ้นมาเพื่อทำงานกับข้อมูลประเภทรูปภาพโดยเฉพาะ สิ่งที่แตกต่างจาก ANN คือข้อมูลที่เข้าไปใน CNN (ในที่นี้หมายถึง 2D CNN) นั้นเป็น 3 มิติได้แก่ height, width (มิติเชิงพื้นที่) และ depth (เช่นจำนวน color channel) จากตัวอย่างด้านล่างเป็นภาพขนาด 5 × 5 pixel มี 3 channel (RGB) ซึ่งเห็นได้ว่าเป็นแบบ 3 มิติ สามารถเขียนรูปร่าง (shape) ตาม format ของ PyTorch ออกมาได้ (C, H, W) = (3, 5, 5)

2. โครงสร้างของ CNN
โครงสร้างของ CNN ประกอบด้วย layer 3 ประเภท ได้แก่
- convolutional layer
- pooling layer
- fully-connected layer หรือ dense layer

2.1 Convolutional Layer
เป็นหัวใจ ❤️ ของ CNN ทำหน้าที่ดึง feature ที่สำคัญในรูปภาพออกมาผ่าน kernel หรือ filter โดย kernel มีหน้าตาเป็น matrix ขนาดเล็ก เรียงซ้อนกันตามจำนวน depth ของ input
ค่า parameter ที่สำคัญใน convolutional layer ได้แก่ kernel_size , stride และ padding โดย
- kernel_size: ขนาดของ kernel หรือ receptive field size โดย kernel ที่มีขนาดเล็กจะสามารถดึงข้อมูลออกมาได้ละเอียดกว่าขนาดใหญ่ แต่ขนาดใหญ่จะสามารถทำงานได้เร็วกว่า
- stride: ขนาด step ในการเลื่อน kernel คล้ายกับขนาดของ kernel, stride ที่มีขนาดเล็กกว่าสามารถดึงข้อมูลออกมาได้ละเอียดกว่าขนาดใหญ่
- padding: ความหนา pixel ที่เพิ่มจากขอบของ input เดิม การทำ padding ช่วยในการรักษา feature ที่อยู่บริเวณขอบ อีกทั้งยังสามาถทำให้ขนาดของ output เท่ากับขนาดของ input ด้วย นอกจากนี้ยังสามารถทำกรณีขนาด kernel ใหญ่กว่าขนาดของ input
วิธีการดึง feature จากรูปภาพคือการนำ kernel มาทำ element-wise product หรือ entrywise product หรือ hadamard product (นำสมาชิกที่อยู่ตำแหน่งเดียวกันมาคูณกัน) กับ input ตำแหน่งที่ถูก kernel ครอบ แล้วหาผลรวมของสมาชิกทุกตัว
ขนาดของ output ที่ออกมาสามารถคำนวณได้ตามสูตร

โดย
W: weight ของ input
H: height ของ input
F: ขนาด kernel (receptive field)
P: ขนาด padding
S: ขนาด stride
โดยทั่วไป input, kernel และ stride มีหน้าตาเป็นสี่เหลี่ยมจัตุรัส ดังนั้นที่จริงแล้วค่าของตัวแปรใน 2 สมการด้านบนนั้นเหมือนกัน
ตัวอย่างการคำนวณ output จาก convolutional layer
ตัวอย่างที่ 1
กำหนด input ขนาด 5 × 5 มีค่าด้านในคือ

กำหนด kernel ขนาด 3 × 3 มีค่าด้านในคือ

กำหนด stride = 1, padding = 0
ได้ว่าขนาดของ output ที่จะออกมาคือ (5 -3 + 2×0)/1 + 1 = 3
Step1
เริ่มต้นให้ kernel อยู่ตรงกับมุมบนซ้ายสุดของ input แล้วทำ element-wise product กับ input ตำแหน่งที่ตรงกับ kernel หลังจากนั้นหาผมรวมของค่าใน matrix ผลลัพธ์ จะได้ค่าที่อยู่ใน output

Step2
เลื่อน kernel ไปทางขวาตามค่า stride ซึ่งในที่นี้ก็คือ 1 ดังนั้นเลื่อนไปทางขวา 1 ช่อง แล้วใช้วิธีเดียวกับ step 1 เพื่อหาค่า output

Step3
ทำแบบเดิมกับ step 2

Step4
เมื่อไม่สามารถเลื่อน kernel ไปทางขวาตามขนาดของ stride แล้ว เลื่อน kernel กลับไปด้านซ้ายอีกครั้ง และลงด้านล่างตามค่า stride ซึ่งในที่นี้ก็คือ 1 ดังนั้นเลื่อนไปด้านล่าง 1 ช่อง และใช้วิธีเดิมคำนวณ output

Step5
ทำแบบเดิมไปเรื่อยๆจน kernel ผ่านทุกตำแหน่งใน input
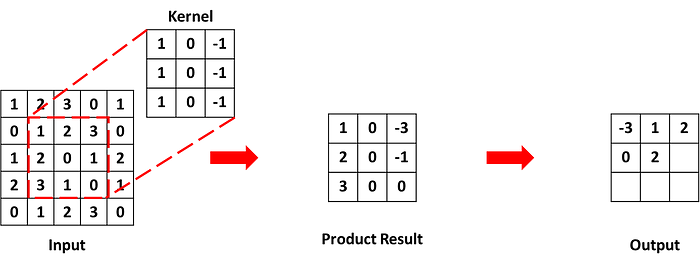




จากตัวอย่างด้านบนสามารถใช้ PyTorch เขียนออกมาได้ว่า
# torch.nn เก็บ module ที่สำคัญในการสร้าง neural network เช่น layer แต่ละชนิด, activation, loss function
import torch.nn as nn
# ใช้ nn.Conv2d สำหรับสร้าง convolution layer สำหรับ 2D CNN
# กำหนด parameter ตามค่าที่ระบุไว้ด้านบน โดย in_channels และ out_channels เท่ากับ 1 เพราะว่า input และ ouput เป็นข้อมูลชั้นเดียว (depth=1)
conv_layer = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, stride=1, padding=0)
# กำหนดค่าใน input, แต่ในที่นี้เป็นข้อมูล 4 มิติ คือ (B, C, H, W) โดย B คือ batch size เพราะว่าในความเป็นจริงเวลา train model ข้อมูลถูกแบ่งออกมาเป็น batch แล้วค่อยเอาเข้าที่ละ batch
# รูปร่างของข้อมูลในที่นี้คือ (1, 1, 5, 5) batch size = 1, channel = 1 ภาพขนาด 5×5
input_tensor = torch.tensor([[[[1, 2, 3, 0, 1],
[0, 1, 2, 3, 0],
[1, 2, 0, 1, 2],
[2, 3, 1, 0, 1],
[0, 1, 2, 3, 0]]]], dtype=torch.float32)
# กำหนดค่าใน kernel ของ convolution layer
conv_layer.weight.data = torch.tensor([[[[1.0, 0.0, -1.0],
[1.0, 0.0, -1.0],
[1.0, 0.0, -1.0]]]], dtype=torch.float32)
# เพราะว่าที่จริงแล้ว output = (input ⊗ kernel) + bias และ ค่า default ของ bias ใน nn.Conv2d คือ True
# ดังนั้นหากไม่ต้องการให้มีการคำนวณ bias สามารถกำหนด bias=False ใน nn.Conv2d ไม่ก็กำหนดให้เท่ากับ 0 ทีหลังก็ได้
conv_layer.bias.data = torch.tensor([0.0], dtype=torch.float32)
# คำนวณ output จาก input ที่ผ่าน convolution layer ที่สร้างขึ้น
output_tensor = conv_layer(input_tensor)ได้ผลลัพธ์ออกมาคือ
tensor([[[[-3., 1., 2.],
[ 0., 2., 0.],
[ 0., 2., 0.]]]], grad_fn=<ConvolutionBackward0>)ตัวอย่างที่ 2
กำหนด input ขนาด 4 × 4 มีค่าด้านในคือ

กำหนด kernel ขนาด 3 × 3 มีค่าด้านในคือ

กำหนด stride = 3, padding = 1
ได้ว่าขนาดของ output ที่จะออกมาคือ (4 -3 + 2×1)/3 + 1 = 2
Step1
เนื่องจากมีการทำ padding ดังนั้นเติมข้อมูลเข้าไปที่ขอบ input ความหนาตามค่า padding ซึ่งในที่นี้ก็คือ 1 ดังนั้นต่อเข้าไปที่ขอบ 1 ช่อง โดยค่าที่อยู่ในส่วนที่เติมเข้าไปคือ 0

Step2
ใช้วิธีเดียวกับตัวอย่างด้านบนคำนวณค่าใน output
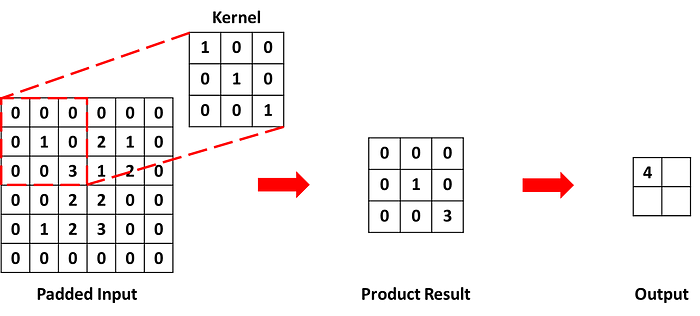
Step3
เลื่อน kernel ไปทางขวาตามค่า stride ซึ่งในที่นี้ก็คือ 3 ดังนั้นเลื่อนไปทางขวา 3 ช่อง แล้วใช้วิธีเดิมหาค่า output

Step4
ทำแบบเดิมไปเรื่อยๆจน kernel ผ่านทุกตำแหน่งใน input


จากตัวอย่างด้านบนสามารถใช้ PyTorch เขียนออกมาได้ว่า
import torch.nn as nn
conv_layer = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, stride=3, padding=1)
input_tensor = torch.tensor([[[[1, 0, 2, 1],
[0, 3, 1, 2],
[0, 2, 2, 0],
[1, 2, 3, 0]]]], dtype=torch.float32)
conv_layer.weight.data = torch.tensor([[[[1.0, 0.0, 0.0],
[0.0, 1.0, 0.0],
[0.0, 0.0, 1.0]]]], dtype=torch.float32)
conv_layer.bias.data = torch.tensor([0.0], dtype=torch.float32)
output_tensor = conv_layer(input_tensor)ได้ผลลัพธ์ออกมาคือ
tensor([[[[4., 1.],
[1., 2.]]]], grad_fn=<ConvolutionBackward0>)จากตัวอย่างด้านบนเห็นได้ว่าการคำนวณ output จาก convolution layer นอกจากค่าใน input แล้ว ยังต้องกำหนดค่าที่อยู่ใน kernel ซึ่งในทางปฎิบัติเราไม่กำหนดค่าใน kernel โดยตรง แต่เรามองว่ามันคือ weight ของโมเดลซึ่งจะมีการปรับเองระหว่าง train model
จากข้อจำกัดของ ANN ที่เกริ่นนำไปข้างต้นหาก input เป็น รูปภาพสีขนาด 64 × 64 ถ้าใช้ ANN โดยตรง weight ที่ต้องใช้ใน hidden layer แรกคือ 12,288 แต่ถ้าใช้ convolution layer ที่มี kernel ขนาด 3 × 3 จะต้องใช้ weight เพียง 3 × 3 × 3 = 27 เท่านั้น! (kernel ขนาด 3 × 3 มีทั้งหมด 9 ช่อง แต่ละช่องก็มี 1 weight, ภาพสีมี 3 channel ดังนั้นใช้ kernel 3 ชั้น ซึ่งก็มี weight ของใครของมัน ดังนั้นรวมทั้งหมดคือ 3 × 9 = 27)
2.2 Pooling Layer
มีเป้าหมายเพื่อลดจำนวน parameter และความซับซ้อนในการคำนวณของโมเดล จากการลดขนาดเชิงพื้นที่ของ input ประเภทของ pooling ที่มักใช้คือ “max-pooling”
คล้ายกับ convolutional layer, pooling layer มี parameter ที่สำคัญคือ kernel_size และ stride วิธีคำนวณผลลัพธ์จาก pooling ก็คล้ายกับ convolution layer คือ พิจารณา input ส่วนที่ถูก kernel ครอบ ถ้าเป็น max-pooling ก็เลือกค่าสูงสุดใน input ส่วนนั้นมาเป็นผลลัพธ์ วิธีการคำนวณขนาดของ output ก็ใช้สูตรเดียวกับของ convolution layer แต่เนื่องจากเป้าหมายของการทำ pooling คือการลดขนาดของ input ดังนั้นโดยทั่วไปจะไม่มีการทำ padding
ตัวอย่างการคำนวณ output จาก pooling layer
ตัวอย่างที่ 1
กำหนด input ขนาด 4 × 4 มีค่าด้านในคือ

กำหนด kernel ขนาด 2 × 2, stride = 2
ได้ว่าขนาดของ output ที่จะออกมาคือ (4 - 2 + 2×0)/2 + 1 = 2
Step1
คล้ายกับ convolution layer เริ่มต้นที่มุมบนซ้ายสุด เลือกค่า input ส่วนที่ตรงกับ kernel ที่มีค่ามากที่สุดเป็นค่าของ output

Step2
เลื่อน kernel ไปทางขวาตามค่า stride ซึ่งในที่นี้ก็คือ 2 ดังนั้นเลื่อนไปทางขวา 2 ช่อง แล้วใช้วิธีเดียวกับ step 1 หาค่า output

Step3
ทำแบบเดิมไปเรื่อยๆจน kernel ผ่านทุกตำแหน่งใน input

จากตัวอย่างด้านบนสามารถใช้ PyTorch เขียนออกมาได้ว่า
import torch.nn as nn
# ใช้ nn.MaxPool2d สำหรับสร้าง max-pooling layer สำหรับ 2D CNN
pool_layer = nn.MaxPool2d(kernel_size=2, stride=2)
input_tensor = torch.tensor([[[[1, 0, 2, 3],
[2, 5, 1, 0],
[3, 1, 2, 2],
[1, 0, 2, 1]]]])
output_tensor = pool_layer(input_tensor)ได้ผลลัพธ์ออกมาคือ
tensor([[[[5, 3],
[3, 2]]]])ตัวอย่างที่ 2
กำหนด input ขนาด 4 × 4 มีค่าด้านในเหมือนกับตัวอย่างที่ 1, kernel ขนาด 2 × 2, stride = 1
ได้ว่าขนาดของ output ที่จะออกมาคือ (4 - 2 + 2×0)/1 + 1 = 3
Step1
ใช้วิธีเดียวกับด้านบนคำนวณค่า output

Step2
เลื่อน kernel ไปทางขวาตามค่า stride ซึ่งในที่นี้ก็คือ 1 ดังนั้นเลื่อนไปทางขวา 1 ช่อง แล้วใช้วิธีเดิมหาค่า output

Step3
ทำแบบเดิมไปเรื่อยๆจน kernel ผ่านทุกตำแหน่งใน input

จากตัวอย่างด้านบนสามารถใช้ PyTorch เขียนออกมาได้ว่า
import torch.nn as nn
pool_layer = nn.MaxPool2d(kernel_size=2, stride=1)
input_tensor = torch.tensor([[[[1, 0, 2, 3],
[2, 5, 1, 0],
[3, 1, 2, 2],
[1, 0, 2, 1]]]])
output_tensor = pool_layer(input_tensor)
output_tensor ได้ผลลัพธ์ออกมาคือ
tensor([[[[5, 5, 3],
[5, 5, 2],
[3, 2, 2]]]])จากตัวอย่างด้านบนเห็นได้ว่ากรณีที่ขนาด kernel มีค่ามากกว่า stride จะเกิดการ overlap ขึ้นระหว่างการทำ pooling ซึ่งทำให้โมเดลมีความ sensitive กับตำแหน่งของค่าใน input มากกว่าที่ไม่เกิด overlap จากภาพด้านล่างกรณีที่ไม่เกิด overlap (ภาพซ้ายบน) ข้อมูลถูกดึงออกมาอย่างสม่ำเสมอทั่วทั้ง input, แต่กรณีที่เกิด overlap และข้อมูลใน input เหมือนเดิม (ภาพขวาบน) ข้อมูลเดิมถูกดึงออกมาซ้ำกันถึง 4 ครั้ง เพราะว่าตำแหน่งของค่านั้น (ในที่นี้คือเลข 5) อยู่ในส่วน overlap และเป็นค่าสูงสุดของทั้ง 4 ช่วงนี้ แต่ถ้าย้ายเลข 5 ไปอยู่มุมบนซ้าย (ภาพล่างสุด) ข้อมูลก็ถูกดึงสม่ำเสมอเหมือนเดิม

ดังนั้นข้อดีของการไม่เกิด overlap คือสามารถดึง feature ออกมาได้กระจายมากกว่า, สามารถรับมือกรณีที่มี input บางส่วนมีค่าผิดปกติ แต่การเกิด overlap ก็ช่วยให้เกิด overfitting ยากขึ้น เพราะโมเดลเรียนรู้จากข้อมูลในภาพรวมที่มีรายละเอียดยิบย่อยน้อยกว่า
2.3 Fully-connected Layer หรือ Dense Layer
fully-connected (FC) layer ก็คือ layer แบบเดียวกับที่อยู่ใน ANN, node ใน layer ปัจจุบันทุก node เชื่อมต่อกับทุก node ใน layer ถัดไป ทำหน้าที่คำนวนคะแนนความน่าจะเป็นของแต่ละ class สำหรับโมเดล classification
เนื่องจากข้อมูลที่ออกจาก convolution และ pooling layer เป็นรูปแบบ 3 มิติ แต่ข้อมูลที่เข้าใน FC คือ 1 มิติ ดังนั้นต้องมีการทำ “flatten” ก่อนตามภาพด้านล่าง

3. ตัวอย่างการสร้าง CNN (VGG16) ด้วย PyTorch อย่างง่าย
VGG หรือ Very Deep Convolutional Networks คือโมเดล CNN มาตรฐานตโมเดลหนึ่งที่ถูกพัฒนาให้สามารถทำงานกับภาพขนาดใหญ่ได้ดีขึ้น โดยอาศัยจำนวน layer ที่มาก (โมเดลมีความลึก)
VGG มีอยู่หลาย version เช่น VGG11, VGG13, VGG16, VGG19 โดยเลขด้านหลังบ่งบอกถึงจำนวน convolutional layer รวมกับ dense layer โดย VGG ที่ได้รับความนิยมแพร่หลายมากที่สุดคือ VGG16 มี convolutional layer 13 layers และ dense layer 3 layers
3.1 แนะนำสิ่งที่สำคัญใน VGG เพิ่มเติม
ก่อนที่จะเริ่มสร้าง VGG มี 3 สิ่งต้องแนะนำเพิ่มเติมก่อน เพราะอยู่ใน VGG เช่นกันคือ
1. ReLU
ReLU (Rectified Linear Unit) คือ activation function (function ที่ใช้คำนวณ output จาก ANN) โดยหาก input มีค่ามากกว่าหรือเท่ากับ 0 output จะออกมาเท่ากับ input แต่หาก input น้อยกว่า 0 output จะเท่ากับ 0 ตามกราฟด้านล่าง

2. Flatten
ตามที่ได้กล่าวในส่วนของ FC ด้านบน flatten คือการแปลงข้อมูลหมายมิติให้อยู่ในรูปของ vector 1 มิติ ตามภาพด้านล่าง

ความยาวของ vector = จำนวน channel x height x width ของ input เช่นได้ output จาก pooling layer มีรูปร่างคือ (512, 7, 7) ดังนั้นเมื่อผ่านการทำ flatten จะได้ vector ที่มีความยาว 512 × 7 × 7 = 25088
3. Dropout
คือการสุ่มไม่ให้บาง node ส่งข้อมูลไปยัง layer ถัดไปใน FC เพื่อแก้ปัญหา overfitting ตามภาพด้านล่าง
3.2 สร้าง VGG16 ด้วย PyTorch อย่างง่าย
ตาม paper ของ VGG รูปภาพที่เป็น input เข้าไปในโมเดลคือภาพสี RGB ขนาด 224 × 224, ใน convolutional layer in_channels และ out_channels ของแต่ละ layer แตกต่างกันบ้าง แต่สิ่งที่เหมือนกับคือกำหนด kernel_size=3 , stride=1 และ padding=1 , pooling layer กำหนด kernel_size=2 และ stride=2
โครงสร้างของ VGG16 เป็นไปตามภาพด้านล่าง โดยทั่วไปเราแบ่ง convolutional layer ทั้ง 13 เป็น 5 ก้อน (block) ตามจำนวน channel (หรือก็คือจำนวน filter) ได้แก่ 64, 128, 256 และ 512 (block 4, 5 ขนาดเท่ากัน) โดยมี max pooling ปิดท้ายแต่ละก้อน นอกจากนี้สังเกตได้ว่าทุก output ที่ออกจาก convolutional และ FC layer ต้องผ่าน ReLU ก่อน เพื่อไม่ให้โมเดลกลายเป็น linear function ธรรมดา

ดังนั้นสามารถใช้ตัวอย่างการสร้างแต่ละ layer ที่แสดงในตอนที่ 2 สร้าง VGG16 ได้ดังนี้
import torch.nn as nn
# สร้าง class โมเดล VGG16
class VGG16(nn.Module):
# n_channels ตามประเภทรูปภาพ ถ้าเป็นภาพ grayscale หรือ binary กำหนดเท่ากับ 1 ถ้าเป็นภาพสีกำหนดเท่ากับ 3
# n_classes ตามจำนวน class ที่ต้องการแบ่ง (กำหนดเท่ากับ 1000 เพราะว่าตาม paper โมเดลทดสอบกับ ImageNet dataset ที่มี 1000 classes)
def __init__(self, n_channels=3, n_classes=1000):
super().__init__()
# ใช้ nn.Sequential เพื่อสร้างทำดับการเข้าแต่ละ layer ของ input มัดไว้ด้วยกัน
self.layers = nn.Sequential(
# conv ก่อนที่ 1
nn.Conv2d(in_channels=n_channels, out_channels=64, kernel_size=3, stride=1, padding=1),
# nn.ReLU เพื่อใช้ ReLU, กำหนด inplace=True เพื่อให้นำ output ไปเก็บไว้ใน memory ช่องเดียวกับ input
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# conv ก้อนที่ 2
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# conv ก้อนที่ 3
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# conv ก้อนที่ 4
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# conv ก้อนที่ 5
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# ใช้ nn.Flatten สำหรับทำ flatten เพื่อเตรียมนำข้อมูลเข้า FC
nn.Flatten(),
# ใช้ nn.Linear เพื่อสร้าง FC
nn.Linear(in_features=25088, out_features=4096),
nn.ReLU(inplace=True),
# จาก paper กำหนดให้ dropout ที่ความน่าจะเป็น 0.5
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=n_classes)
)
# กำหนดการดำเนินการกับ input ที่เข้ามาใน class
def forward(self, x):
return self.layers(x)สามารถดูสรุปข้อมูลโครงสร้างโมเดลได้โดยใช้ torchsummary.summary โดยจะแสดงรูปร่างของ output ในแต่ละ layer และจำนวน parameter
from torchsummary import summary
model = VGG16(n_channels=3, n_classes=1000)
# กำหนดว่า input คือภาพสีขนาด 224 x 224
summary(model, (3, 224, 224))ได้ผลลัพธ์คือ
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 224, 224] 1,792
ReLU-2 [-1, 64, 224, 224] 0
Conv2d-3 [-1, 64, 224, 224] 36,928
ReLU-4 [-1, 64, 224, 224] 0
MaxPool2d-5 [-1, 64, 112, 112] 0
Conv2d-6 [-1, 128, 112, 112] 73,856
ReLU-7 [-1, 128, 112, 112] 0
Conv2d-8 [-1, 128, 112, 112] 147,584
ReLU-9 [-1, 128, 112, 112] 0
MaxPool2d-10 [-1, 128, 56, 56] 0
Conv2d-11 [-1, 256, 56, 56] 295,168
ReLU-12 [-1, 256, 56, 56] 0
Conv2d-13 [-1, 256, 56, 56] 590,080
ReLU-14 [-1, 256, 56, 56] 0
Conv2d-15 [-1, 256, 56, 56] 590,080
ReLU-16 [-1, 256, 56, 56] 0
MaxPool2d-17 [-1, 256, 28, 28] 0
Conv2d-18 [-1, 512, 28, 28] 1,180,160
ReLU-19 [-1, 512, 28, 28] 0
Conv2d-20 [-1, 512, 28, 28] 2,359,808
ReLU-21 [-1, 512, 28, 28] 0
Conv2d-22 [-1, 512, 28, 28] 2,359,808
ReLU-23 [-1, 512, 28, 28] 0
MaxPool2d-24 [-1, 512, 14, 14] 0
Conv2d-25 [-1, 512, 14, 14] 2,359,808
ReLU-26 [-1, 512, 14, 14] 0
Conv2d-27 [-1, 512, 14, 14] 2,359,808
ReLU-28 [-1, 512, 14, 14] 0
Conv2d-29 [-1, 512, 14, 14] 2,359,808
ReLU-30 [-1, 512, 14, 14] 0
MaxPool2d-31 [-1, 512, 7, 7] 0
Flatten-32 [-1, 25088] 0
Linear-33 [-1, 4096] 102,764,544
ReLU-34 [-1, 4096] 0
Dropout-35 [-1, 4096] 0
Linear-36 [-1, 4096] 16,781,312
ReLU-37 [-1, 4096] 0
Dropout-38 [-1, 4096] 0
Linear-39 [-1, 1000] 4,097,000
================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 218.78
Params size (MB): 527.79
Estimated Total Size (MB): 747.15
----------------------------------------------------------------หรือถ้าต้องการง่ายกว่านี้ก็สามารถใช้ VGG16 ที่มีอยู่แล้วใน PyTorch โดยโมเดลนี้ถูกเก็บไว้ใน torchvision.models ถ้าดูโครงสร้างด้านในจะพบว่าเหมือนกับที่เราสร้างด้านบนเด๊ะ
import torchvision.models as models
from torchsummary import summary
model = models.vgg16()
summary(model, (3, 224, 224))ได้ผลลัพธ์คือ
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 224, 224] 1,792
ReLU-2 [-1, 64, 224, 224] 0
Conv2d-3 [-1, 64, 224, 224] 36,928
ReLU-4 [-1, 64, 224, 224] 0
MaxPool2d-5 [-1, 64, 112, 112] 0
Conv2d-6 [-1, 128, 112, 112] 73,856
ReLU-7 [-1, 128, 112, 112] 0
Conv2d-8 [-1, 128, 112, 112] 147,584
ReLU-9 [-1, 128, 112, 112] 0
MaxPool2d-10 [-1, 128, 56, 56] 0
Conv2d-11 [-1, 256, 56, 56] 295,168
ReLU-12 [-1, 256, 56, 56] 0
Conv2d-13 [-1, 256, 56, 56] 590,080
ReLU-14 [-1, 256, 56, 56] 0
Conv2d-15 [-1, 256, 56, 56] 590,080
ReLU-16 [-1, 256, 56, 56] 0
MaxPool2d-17 [-1, 256, 28, 28] 0
Conv2d-18 [-1, 512, 28, 28] 1,180,160
ReLU-19 [-1, 512, 28, 28] 0
Conv2d-20 [-1, 512, 28, 28] 2,359,808
ReLU-21 [-1, 512, 28, 28] 0
Conv2d-22 [-1, 512, 28, 28] 2,359,808
ReLU-23 [-1, 512, 28, 28] 0
MaxPool2d-24 [-1, 512, 14, 14] 0
Conv2d-25 [-1, 512, 14, 14] 2,359,808
ReLU-26 [-1, 512, 14, 14] 0
Conv2d-27 [-1, 512, 14, 14] 2,359,808
ReLU-28 [-1, 512, 14, 14] 0
Conv2d-29 [-1, 512, 14, 14] 2,359,808
ReLU-30 [-1, 512, 14, 14] 0
MaxPool2d-31 [-1, 512, 7, 7] 0
AdaptiveAvgPool2d-32 [-1, 512, 7, 7] 0
Linear-33 [-1, 4096] 102,764,544
ReLU-34 [-1, 4096] 0
Dropout-35 [-1, 4096] 0
Linear-36 [-1, 4096] 16,781,312
ReLU-37 [-1, 4096] 0
Dropout-38 [-1, 4096] 0
Linear-39 [-1, 1000] 4,097,000
================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 218.78
Params size (MB): 527.79
Estimated Total Size (MB): 747.15
----------------------------------------------------------------